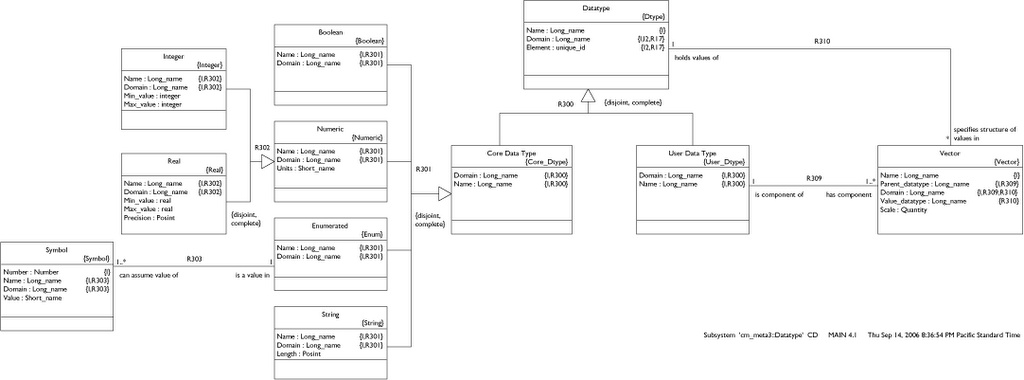
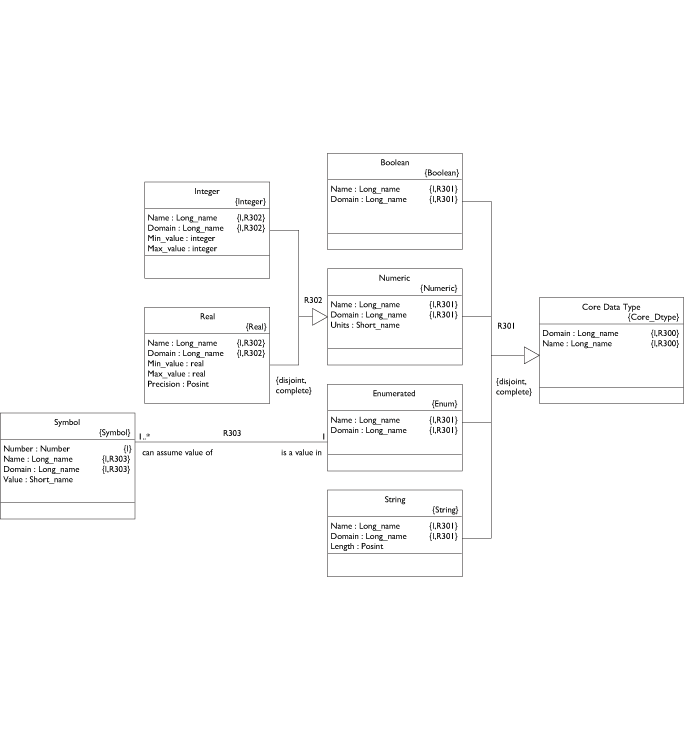
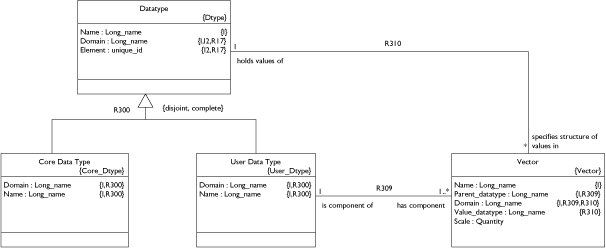
A parser will yield the elements described here so, at this level, we don't care about notation or syntax. We do want to distill the essence of an action block specification so that we can build a machine that can execute any action block. Rather than build a full blown action language all at once, it is probably best to define the core elements and implement a primitive machine. Then, with some experimentation, we can extend or rethink the language to evolve something truely useful.
Ss the goal of these notes is sort out the concepts required to support the specification of action components as well as the run-time execution of those components in an action language interpreter. Whereas SMALL and SCRALL focus on syntax primarily, we need to sort out the underlying mechanics and integration with the metamodel. The next step will be to start modeling those concepts. Incremental versions of the action language metamodel will be posted at sourceforge for anyone interested.
Here are some questions we hope to answer:
- What configurations of data are exchanged? How many do we need?
- Do we have just one flow that can transfer any kind of data?
- Or do we create a separate flow type for each configuration of data?
- What kind of processes do we have? What are the inputs and outputs?
- ?
We must also keep in mind that varying degrees of parallelism are possible depending on the target architecture. So we must be careful not to define structures that perform only in a sequential context.
Key
Let's use the following symbols: [ a | b ] - a or b
{ c } - zero, one or many c's
1{ d } - at least one d
< e > - zero or one e - optional
( d, f ) - d and f are grouped together in the same flow
g - exactly one - g is required
{ c } - zero, one or many c's
1{ d } - at least one d
< e > - zero or one e - optional
( d, f ) - d and f are grouped together in the same flow
g - exactly one - g is required
Action Block
An action block is a bundle of action language associated with a state, class operation or service. Action language consists of nodes (processes and stores) connected by flows.Flows
A flow transfers data into, out of, or between nodes. Each flow has a unique numbered identifier and may be optionally named. Duplicate names in the same action block are allowed.Every flow specifies at least one source and destination. The types and quantities of sources and destinations depends on the flow type.
Specification: Unique_id < Descriptive_name >
Object Flow
An object flow transfers zero or many object references. This flow can be generated by either a selector or a creator process.Specification: None
Source: [ object_pool | selector | creator ]
Destination: [ object_pool | transmitter | eraser | tester ]
Run-time content: { object_reference }
Uses:
Populate object pool from selector or creator
Supply references to an eraser for deletion
Transfer object pool to other object processors (to be defined later)
Provide input to a tester to evaluate cardinality
Supply references to an eraser for deletion
Transfer object pool to other object processors (to be defined later)
Provide input to a tester to evaluate cardinality
Attribute Flow
An attribute flow specifies the transfer of one or more attribute name:value pairs. All attributes in a flow must belong to the same class. Each value must have a data type that matches that of its attribute.Specification: class_name, 1{ attribute_name }
Source: [ object_pool | transform ]
Destination: [ object_pool | transform | tester | creator ]
Run-time content: { < object_reference > 1{ attribute_name:value } }
Uses:
Read attribute values using object references in an object pool
Write attribute values of a specific object
Write attribute values the same for all objects referenced in an object pool
Supply data to a transform or tester
Supply attribute initialization values to a creator (Cannot carry an object reference)
Write attribute values of a specific object
Write attribute values the same for all objects referenced in an object pool
Supply data to a transform or tester
Supply attribute initialization values to a creator (Cannot carry an object reference)
When writing to specific objects during run-time, the following data is expected:
{ object_ref 1{ attr_name:value }
Each flowing object reference is accompanied by one or more name:value pairs. To obtain the object reference, the origin of the flow must trace back to an object pool store or creator process.An attribute flow into an object pool containing only name:value pairs and no object reference will write all objects referenced in the pool to the same values.
{ attr_name:value }
We could use this example to setThe following data streams when reading attribute values from an object pool:
{ object_ref 1{ (attr_name:value) }
Here we see that each data item includes an object reference with at least one accompanying attribute name, value pair. The syntax above does not suggest any particular implementation. You don't have to send an attribute name with each value. But there must be some mechansim to ensure that the attribute of each value in an attribute flow can be determined during runtime.
Value Flow
A value flow transfers a single value not associated with any attribute. Each value conforms to a defined user or core data type. Consequently, a value may be arbitarily complex.Specification: None
Source: [ value_store | transform | service ]
Destination: [ value_store | transform | tester | service | selector ]
Run-time content: value
Uses:
Transfer a temporary value in and out of a value store
Output a value from a class operation, transform or service
Transmit a value to a transmitter for inclusion in a signal
Transmit a comparison value to a selector criteria expression
Output a value from a class operation, transform or service
Transmit a value to a transmitter for inclusion in a signal
Transmit a comparison value to a selector criteria expression
Status Flow
A process executes when all of its required input data is available. This means that multiple processes could potentially execute in parallel. But we might want to ensure that certain processes wait, even though data is available, until that data is refined further. Or an upstream decision might preclude invocation of a certain process.A status flow communicates a boolean condition to a downstream process to effect or negate execution. If a status flow is enabled during run-time, the condition is enabled. A process may not execute until all input control flows have been enabled and all input data is available.
Before considering the run-time content of a status flow, we need to understand how flows are managed in general. Every flow, regardless of type, starts off in an "inactive" state. This means that the flow has not yet been populated with any data. Once a flow is populated by whatever process or store provides its input, the flow enters the "activated" state. This means that data is now available. The content of an "active" flow may be "empty". (An object selection that returns no references, for example, would populate an object flow with zero object references). Once all data in a flow has been consumed, the flow enters a final "consumed" state.
When a status flow leaves its "inactive" state, it must be set to either true or false. Any process receiving the false input will not execute. True means that the process may execute. The name of the flow reflects its condition when set. Let's say the name of the flow is "Max Pressure Exceeded" and it feeds into a process named "Close valve". The process may execute only if the value of the flow is True.
Status might be enabled repeatedly for a series of object references. The example taken from figure 6.16.1 of the SMALL paper shows this situation. Crates are sorted into large and small sizes. A flow of object references in SMALL, each with an attached guard condition, flows to two separate attribute write processes.
Each status flow in this example flows object references as well as status.
Specification: None
Source: tester
Destination: any process, including another tester
Run-time content: <>
There are some cases where, instead of a status flow, a value flow with a boolean data type could be used to similar effect. But it would not be possible to preclude execution of a downstream process with this method.
Nodes
A node is either a Store or a Process. Some configuration of data can flow into a node, out of a node or in both directions.Stores
A store is a node where data is organized for access by one or more flows. It is more accurate to say that a store makes data available than to say that anything is actually being stored. They are freshly initiated when an action block is invoked and destroyed when the action block completes. So the scope of a store, regardless of type, is the current action block.Object Pool
An object pool stores a set of object references. The object references may be created by the output object flow of either a selector or an object creator. Every object pool has exactly one object flow input. During run-time, an object pool may receive zero, one or many object references. So it is possible to end up with an empty object pool after the object flow is activated.Any number of attribute flows may enter an object pool. Each such flow specifies a write to the attributes of any objects referenced in the pool. Also, any number of attribute flows may stem from an object pool. Each such flow specifies the reading of attribute values from referenced objects.
Flows In: { attribute } { object }
Flows Out: { attribute } { object }
Each action block in an instance based state has automatic access to an object pool initialized to contain a reference to the current instance. This special object pool is always named "self". Not sure whether we need an object flow to fill this store or whether we make a special rule and say that the self store has no input.
Value Store
A value store holds a single value defined by a data type. Consequently the content of a value store can be arbitrarily complex. A value store is populated by at least one value flow. Any write to a value store replaces any prior value. A value flow that exits a value store reads the current value.A parameter value in a state action block or a class operation has no input value flow. The value is automatically made available when the block is initialized.
Flows In: { value }
Flows Out: { value }
Processes
A process is a specialized activity that has exercises some influence on metamodel content. The inputs, outputs and activity depends on the process type.Selector
A selector takes as input a class, a quantity [ 1 | * ], an optional criteria expression and an optional path expression. It locates the specified object or objects in the designated class and outputs an object flow populated with matching object references. If no matching objects are found, zero references are produced in the object flow.Flows In: { status } { value }
Flows Out: object
Specification: ( class_name ) ( quantity ) < criteria > < path >
Creator
A creator makes a new instance of an object. A reference to the newly created object may be provided by an output object flow. An input attribute flow can be used to initialize any of the object's attributes.Specification: class_name
Flows In: { status } < attribute >
Flows Out: < object >
Eraser
An eraser deletes any objects referenced in an incoming object flow.Flows In: { status } object
Transmitter
A transmitter accepts an object flow and value flow for each parameter. A signal is generated to each object referenced in the flow.Specification: event_specification { value_flow_name, parameter_name }
Flows In: { status } { object } { value }
Tester
A tester accepts status, value and/or attribute flows and produces one or more status flows.Specification: Internal comparison expressions (NOT an action block)
Flows In: { status } { value } { attribute }
Flows Out: 1{ status }
Transform
A transform is a process that, as its name implies, transforms one or more input values to produce a one or more output values. Calculations may be performed, data manipulated and coverted, values tested and assignments made. A transform cannot directly access the class or state models. This means that objects (including "self") may not be selected, attributes read or written or signals generated. Local value stores may be allocated and accessed. A transform cannot produce a status flow - you need a tester process for that.Specification: Internal transformation expressions (NOT an action_block)
Flows In: { status } { attribute } { value }
Flows Out: { attribute } { value }
Example:
Transform Compute_volume
Inputs( Attribute_flow:Dimensions )
Output( Attribute_flow:Volume )
Volume.Volume = Dimensions.Length * Dimensions.Width * Dimensions.Depth
Volume.Object = Dimensions.Object
In the example above, a transform named Compute_volume is defined. It's single input is declared as an attribute flow. The local name Dimensions is applied. An output attribute flow is declared and named Volume. The L, W, D components of the input flow were defined outside the transform, but can be referenced internally. The single component V of the output flow is dynamically declared internally. It can then be referenced downstream. The object reference received in the Dimensions attribute flow is passed along to the Volume attribute flow.
Service
A service is a blackbox process provided by either an external service domain or in the caller's domain. No model references such as objects or attributes may be exchanged with the caller. Only status and values may be communicated.Flows In: { status } { value }
Flows Out: { status } { value }
Specification: action_block
Operation
An operation is an activity defined on a class independent of any state chart. Operations are object-based so that a separate context executes for each object. All selected object references remain available to any invoked operation. This makes sense since the object references in an object pool are valid until the state action completes and the operation must return before that. An operation may produce a single value output. (When we design the exception throw-catch mechansim there will be an additional way for an operation to pass data out).Flows In: { status } { value } { object } { attribute }
Flows Out: { status } { value } { object } { attribute }
Specification: action_block
Conclusion
Again, these are just rough notes in preparation for the modeling activity. As usual, the process of modeling will ferret out inconsistency, ambiguity, self contradiction and gaping holes in logic. All of which are surely present! Nonetheless, I thought it might be helpful to expose the current thinking. Feel free to comment if you see any trouble spots or feel I'm heading down the wrong road or have any theory to contribute.- Leon